


LLMs.txt คืออะไร? พร้อมวิธีทำไฟล์เพื่อบอกทาง AI
บทนำ
ในยุคที่ AI และ Large Language Models (LLMs) อย่าง ChatGPT หรือ Gemini กลายเป็นส่วนหนึ่งของชีวิตประจำวันของผู้คน โมเดลเหล่านี้เรียนรู้และตอบคำถามจากข้อมูลมหาศาลบนอินเทอร์เน็ต ซึ่งรวมถึง “เว็บไซต์” ของคุณด้วย คำถามสำคัญคือ: คุณต้องการให้ AI เรียนรู้และนำเสนอข้อมูลเกี่ยวกับธุรกิจของคุณในรูปแบบไหน? คุณจะควบคุมได้อย่างไรว่าข้อมูลส่วนไหนที่ AI ควรหรือไม่ควรนำไปใช้? ดังนั้น, การทำความเข้าใจว่า LLMs.txt คืออะไร จึงกลายเป็นทักษะใหม่ที่สำคัญอย่างยิ่งสำหรับเจ้าของเว็บไซต์และนักการตลาดทุกคน
หากคุณคุ้นเคยกับไฟล์ robots.txt ที่ใช้บอกทาง “Search Engine Crawler” (เช่น Googlebot) ว่าให้เก็บหรือไม่เก็บข้อมูลหน้าไหน พูดง่ายๆ ก็คือ, LLMs.txt ก็ทำหน้าที่คล้ายกัน แต่เป็นการบอกทาง “AI Crawler” จากบริษัทเทคโนโลยียักษ์ใหญ่ ว่าเราอนุญาตหรือไม่อนุญาตให้พวกเขานำเนื้อหาบนเว็บไซต์ของเราไปใช้ “ฝึกฝน” โมเดล AI ของพวกเขา บทความนี้จะพาคุณไปทำความรู้จัก, ดูความสำคัญ, และสอนวิธีสร้างไฟล์นี้แบบจับมือทำ เพื่อให้คุณสามารถควบคุมอนาคตของแบรนด์บนโลก AI ได้ด้วยตัวเอง
ทำไม LLMs.txt ถึงสำคัญอย่างยิ่งในยุค AI
ก่อนอื่น, การมีไฟล์ LLMs.txt ไม่ได้ส่งผลโดยตรงต่ออันดับ SEO ของคุณในวันนี้ แต่มันคือการวางรากฐานเพื่อ “อนาคต” และการปกป้อง “สินทรัพย์ดิจิทัล” ของคุณ
- ควบคุมการนำเสนอแบรนด์ (Control Your Brand Narrative): คุณสามารถป้องกันไม่ให้ AI นำข้อมูลที่อาจทำให้เกิดความเข้าใจผิด, ข้อมูลเก่า, หรือข้อมูลในส่วนที่ไม่ต้องการให้เผยแพร่ (เช่น หน้าสำหรับสมาชิก) ไปใช้ตอบคำถาม
- ปกป้องลิขสิทธิ์และข้อมูล (Protect Copyright & Data): คุณสามารถ “ห้าม” ไม่ให้ AI นำบทความ, รูปภาพ, หรือข้อมูลเชิงลึกที่คุณสร้างขึ้นอย่างยากลำบาก ไปใช้เป็นส่วนหนึ่งของโมเดลของพวกเขาโดยไม่ได้รับอนุญาต
- ประหยัดทรัพยากรเซิร์ฟเวอร์ (Save Server Resources): การมี AI Crawler เข้ามาเก็บข้อมูลบนเว็บไซต์บ่อยๆ อาจทำให้เซิร์ฟเวอร์ทำงานหนักขึ้น การกำหนดขอบเขตจะช่วยลดภาระในส่วนนี้ได้
วิธีสร้างไฟล์ LLMs.txt (ง่ายกว่าที่คิด!)
โครงสร้างของ LLMs.txt นั้นคล้ายกับ robots.txt มาก โดยใช้คำสั่งพื้นฐานเพียงไม่กี่อย่าง
ขั้นตอนที่ 1: สร้างไฟล์ใหม่
สร้างไฟล์ Text ธรรมดาขึ้นมา แล้วตั้งชื่อว่า llms.txt (ต้องเป็นตัวพิมพ์เล็กทั้งหมด)
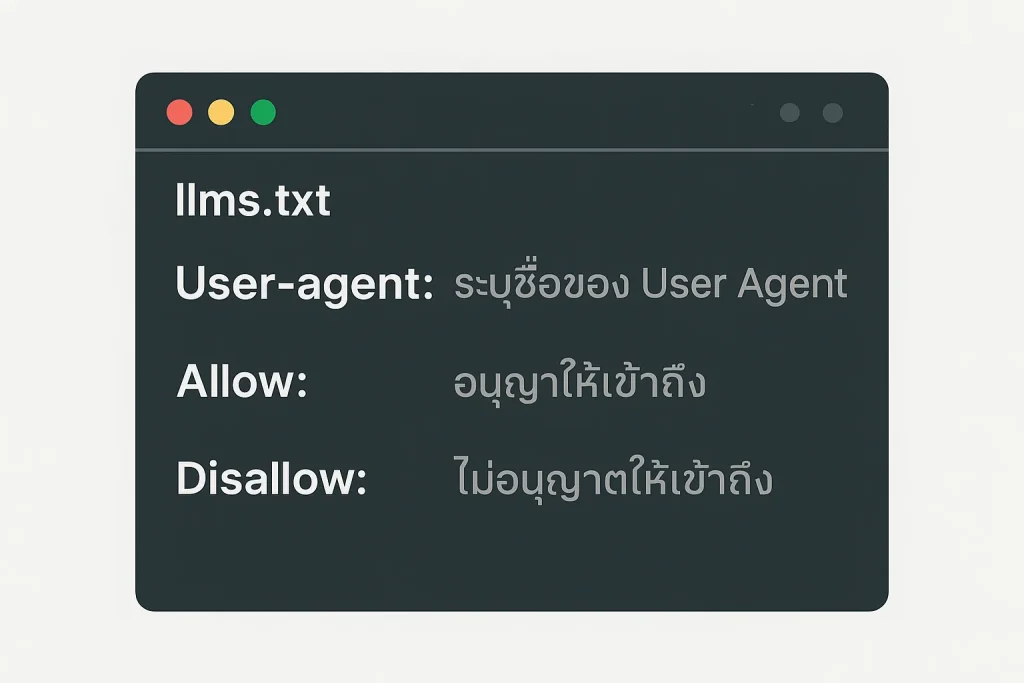
ขั้นตอนที่ 2: ทำความเข้าใจคำสั่งพื้นฐาน
User-agent:คือคำสั่งที่ใช้ระบุชื่อของ AI Crawler ที่เราต้องการจะสั่งAllow:คือคำสั่ง “อนุญาต” ให้เข้าถึง Directory หรือหน้านั้นๆ ได้Disallow:คือคำสั่ง “ไม่อนุญาต” หรือ “ห้าม” เข้าถึง Directory หรือหน้านั้นๆ
ขั้นตอนที่ 3: เขียนคำสั่งลงในไฟล์
ตัวอย่างที่ 1: ต้องการปิดกั้นทุก AI ไม่ให้เข้าถึงทุกส่วนของเว็บ
User-agent: *
Disallow: /
(* หมายถึง Crawler ทุกตัว, / หมายถึงทุกส่วนของเว็บไซต์)
ตัวอย่างที่ 2: ต้องการปิดกั้นเฉพาะ Google-Extended (AI ของ Google)
User-agent: Google-Extended
Disallow: /
(คุณสามารถดูรายชื่อ Crawler ของ AI เจ้าต่างๆ ได้จากแหล่งข้อมูลเช่น The Verge (ลิงก์ภายนอก))
ตัวอย่างที่ 3: ต้องการปิดกั้นทุก AI แต่ “อนุญาต” ให้เข้าถึงได้แค่โฟลเดอร์ /blog/
User-agent: *
Disallow: /
Allow: /blog/
ตัวอย่างที่ 4: ต้องการปิดกั้นไม่ให้ AI เข้าถึงโฟลเดอร์ /private-data/ และ /images/
User-agent: *
Disallow: /private-data/
Disallow: /images/
ขั้นตอนที่ 4: อัปโหลดไฟล์ขึ้นบนเว็บไซต์
นำไฟล์ llms.txt ที่สร้างเสร็จแล้ว อัปโหลดไปไว้ที่ Root Directory ของเว็บไซต์คุณ ซึ่งเป็นที่เดียวกับที่อยู่ของไฟล์ robots.txt
- ตัวอย่าง URL ที่ถูกต้อง:
https://oldschoolagency.in.th/llms.txt
ที่สำคัญที่สุดคือ, การมี เว็บไซต์ที่สร้างอย่างมืออาชีพ จะทำให้การจัดการไฟล์เหล่านี้เป็นเรื่องง่าย
บทสรุป: ก้าวแรกสู่การควบคุมแบรนด์ของคุณในโลก AI
โดยสรุปแล้ว, แม้ว่า LLMs.txt คืออะไร จะยังเป็นเรื่องใหม่ แต่ก็เป็นสิ่งที่ไม่ควรมองข้าม มันคือเครื่องมือง่ายๆ ที่ทรงพลัง ที่มอบอำนาจให้เจ้าของเว็บไซต์สามารถกำหนดทิศทางและปกป้องข้อมูลของตัวเองจากการเข้ามาของ AI ได้ การสร้างไฟล์นี้ตั้งแต่วันนี้ คือการวางรากฐานที่มั่นคงและแสดงวิสัยทัศน์ที่พร้อมสำหรับอนาคต
ท้ายที่สุดนี้, โลกของการตลาดดิจิทัลและเทคโนโลยีเปลี่ยนแปลงอยู่เสมอ การมีพาร์ทเนอร์ที่คอยอัปเดตและให้คำแนะนำเกี่ยวกับเทรนด์ใหม่ๆ จึงเป็นสิ่งจำเป็น ที่ Oldschool Agency เราไม่ได้ดูแลแค่แคมเปญ รับยิงแอด ในปัจจุบัน แต่เรายังมองไปถึงอนาคตเพื่อเตรียมความพร้อมให้กับธุรกิจของคุณ หากคุณต้องการที่ปรึกษาที่เข้าใจทั้งการตลาดในวันนี้และเทคโนโลยีในวันหน้า ติดต่อเราเพื่อวางแผนกลยุทธ์ ได้เลยครับ